さくらのAI Engine 音声合成(TTS)APIの使い方|ずんだもん(VOICEVOX)で読み上げ
こんにちは、UOZUです!
さくらのクラウドで、AIを利用した音声合成「音声合成(TTS)API」)が利用可能になりました。テキストを投げれば、あの「ずんだもん」などの声で喋ってくれるという、非常にユニークなAPIです。
早速触ってみたいと思います!

まずは利用規約の同意から
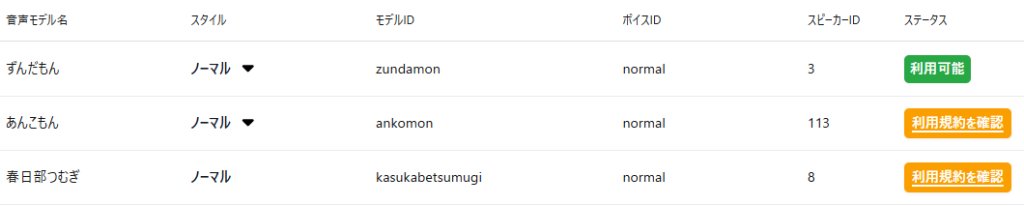
さくらのクラウドのコントロールパネルから「AI Engine」→「利用可能な音声モデル」を開くと、現在は「ずんだもん」を含めて8種類の音声モデルがラインナップされています。
ただし、これらはそのままでは使えませんので、規約への同意を進める必要があります。
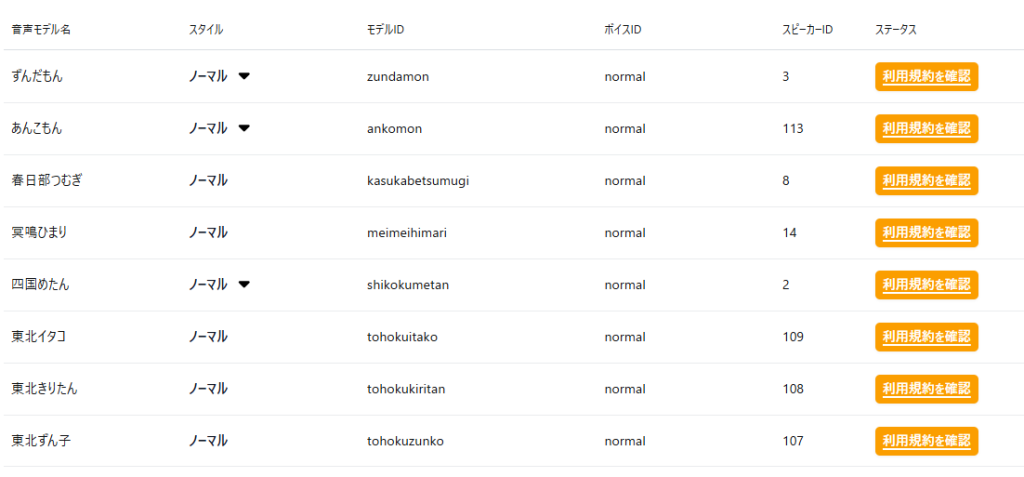
ずんだもんの右端、ステータス列の「利用規約を確認」のボタンをクリックします。
すると、「利用規約」の確認画面が出るので、「音声モデルの利用規約」リンクから規約を読んだあと、「音声モデルの利用規約を確認し、これに同意します」をクリック。
その後、「同意」をクリックします。
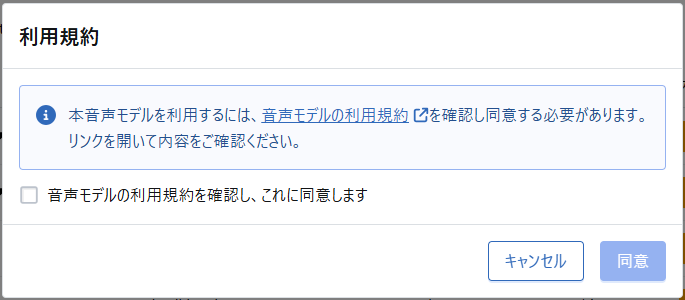
これで「ずんだもん」の音声モデルが利用可能になりました!
※反映まで数分かかることもあるようなので、焦らず待ちましょう。
マニュアルに従い音声の生成
では、マニュアルに従ってサンプル音声を生成してみます。
$ curl --request POST \
--url https://api.ai.sakura.ad.jp/v1/audio/speech \
--header 'accept: audio/wav' \
--header 'Authorization: Bearer xxx-xxxx-xxx-xxxxxxx' \
--header 'Content-Type: application/json' \
--data '{
"model": "zundamon",
"input": "こんにちは、これは音声合成のサンプルです。",
"voice": "normal",
"response_format": "wav"
}' --output ./audio-speech-output.wav$ ll audio-speech-output.wav
-rw-rw-r--. 1 uozu uozu 184876 2月 26 21:27 audio-speech-output.wav無事にWAVファイルが生成されました! 現時点では出力形式がWAVのみのようです。
ファイルサイズが気になる場合は、一度出力した後に ffmpeg などでMP3やOGGにエンコードする必要がありそうです。
また自分が試している限り、稀に {"error":{"message":"This model is not available."}} というエラーが返ることもありましたが、リトライすれば正常に応答しました。
ボイスIDの変更
音声生成では、モデルの指定だけでなく「ボイスID」を変えることで、スタイル(感情)を選べるようになっています。
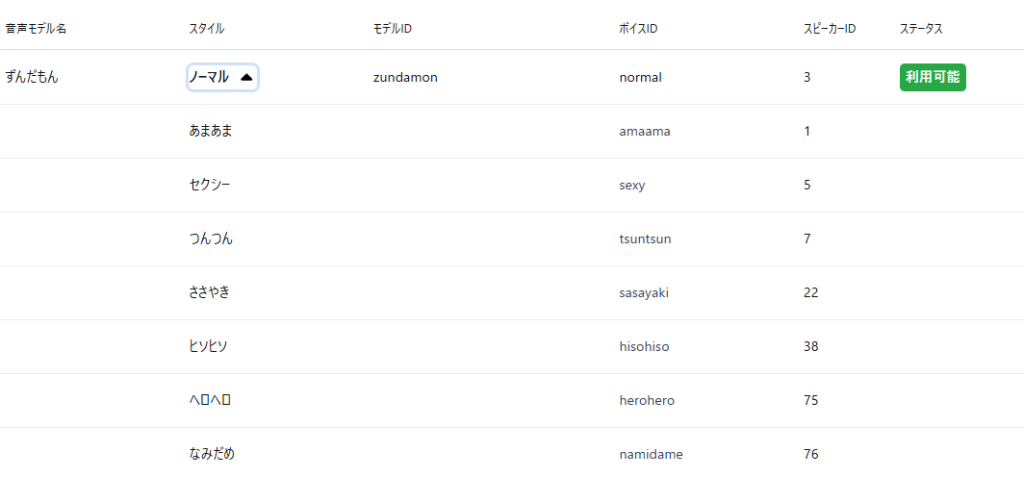
実際にいくつか試してみましたが、感情が乗っているように聞こえます。
あまあま/amaama
セクシー/sexy
つんつん/tsuntsun
最後に
サーバー運用一筋の私としては、なかなか業務で活用するシーンは少ないかもしれませんが、さくらのクラウドという馴染み深いプラットフォームで、これほど簡単に音声合成ができるようになったのは驚きです。
「サーバーの監視通知をずんだもんに読み上げさせたい!」といった遊び心あふれる連携も面白いかもしれませんね。
それではまた!