さくらのAI Engine「RAG API」アップデートを試す:チャンクサイズ指定で回答が変わった話
こんにちは、UOZUです!
2月25日のニュースリリースで、さくらのAI Engine「ドキュメント・RAG API」がチャンクサイズ指定に対応しました。
ドキュメントをどの粒度で分割して読み込ませるかは精度に直結する重要項目なので、さっそく試してみました!
検証用ドキュメントの準備とアップロード
検証用として、Wikipediaの「日本の歴史」をPDF化したもの(History_of_Japan.pdf)を用意しました。
操作ガイドに従い、以下の2パターンでアップロードを試みます。タグ機能を使って「HJ_512」「HJ_256」と識別できるようにしておきます。
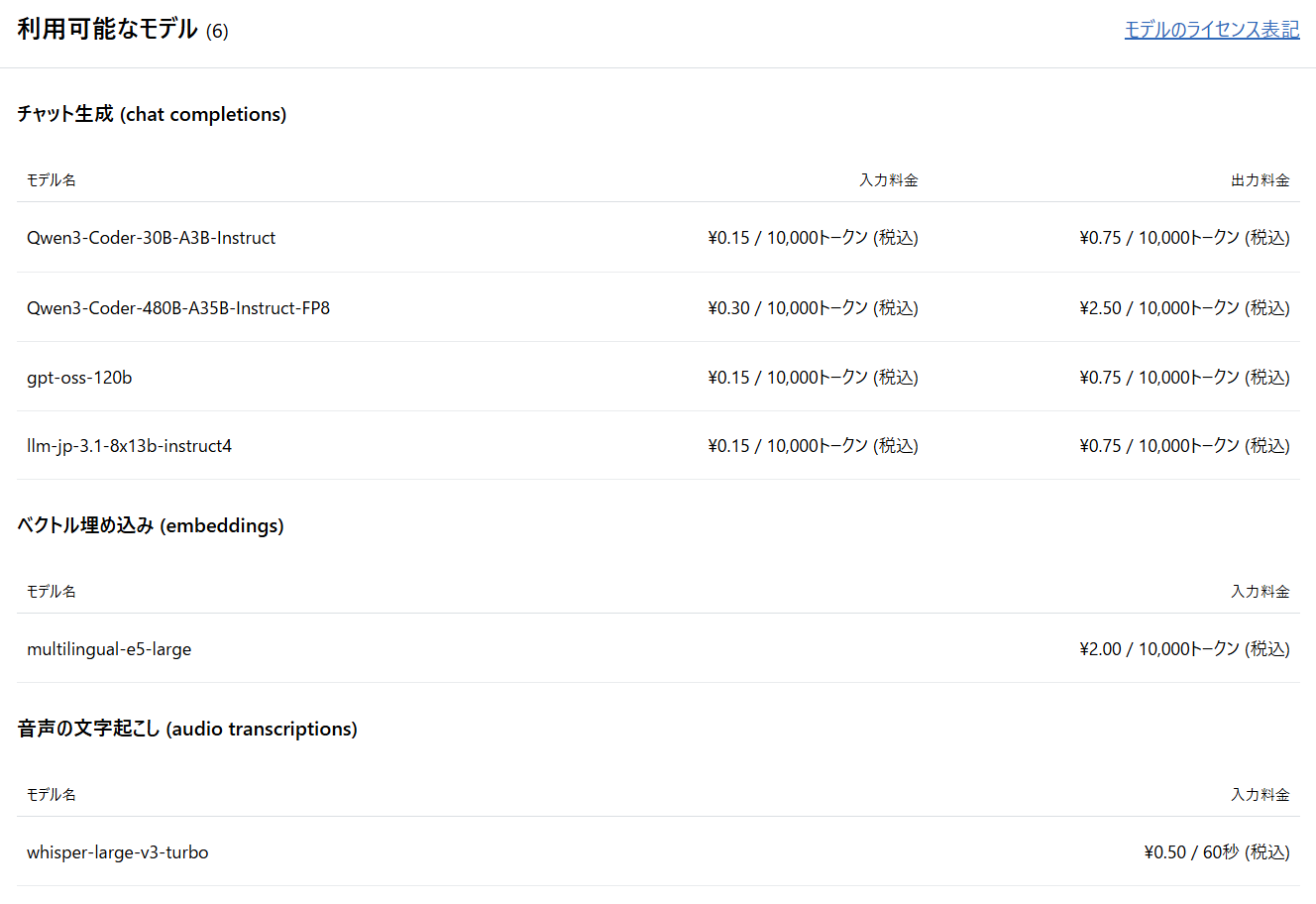
パターンA:チャンクサイズ 512
$ curl --request POST \
--url https://api.ai.sakura.ad.jp/v1/documents/upload/ \
--header 'Accept: application/json' \
--header 'Authorization: Bearer xxxxxx-xxxxxxx-xxxxxx-xxxxx' \
--header 'Content-Type: multipart/form-data' \
--form "file=@History_of_Japan.pdf" \
--form "name=History_of_Japan_512" \
--form "tags=HJ_512" \
--form "model=multilingual-e5-large" \
--form "chunk_size=512"パターンB:チャンクサイズ 256
$ curl --request POST \
--url https://api.ai.sakura.ad.jp/v1/documents/upload/ \
--header 'Accept: application/json' \
--header 'Authorization: Bearer xxxxxx-xxxxxxx-xxxxxx-xxxxx' \
--header 'Content-Type: multipart/form-data' \
--form "file=@History_of_Japan.pdf" \
--form "name=History_of_Japan_256" \
--form "tags=HJ_256" \
--form "model=multilingual-e5-large" \
--form "chunk_size=256"アップロードが完了した時点で、チャンク数(文章の分割数)に明確な差が出ていることが分かります。

検索結果の比較
「明治時代の主な特徴」について、それぞれのタグを指定して「高度な検索」で質問を投げてみたところ、案の定(?)回答の具体性に以下のような差が見受けられました。
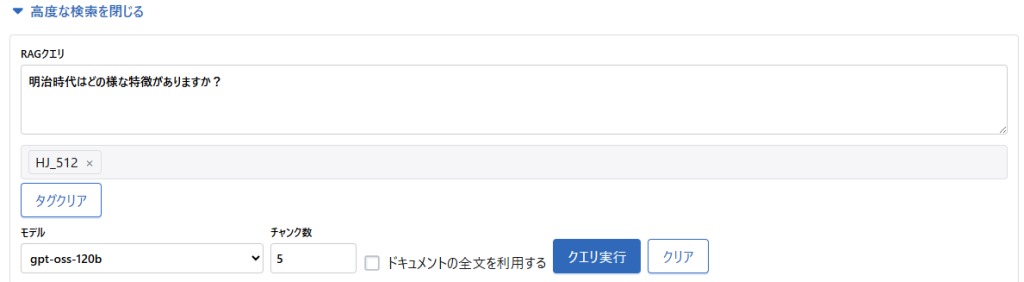
明治時代(1868年 〜 1912年)の主な特徴は、次のように文献で示されています。
項目 内容(文献に基づく)
政治・制度改革 ・廃藩置県、四民平等化、六法(法典)制定、郵便・鉄道・水道などのインフラ整備。
・欧米諸制度の積極的導入(岩倉使節団の視察に基づく)。
・明治維新と呼ばれる一連の改革が実施された。
領土拡張 明治期に琉球王国や北海道(蝦夷地)・千島列島・小笠原諸島を完全に日本領に編入し、国境を画定した。
文化・思想の揺れ ・欧化主義(西洋化)と国粋主義(日本的価値観)の対立が顕在化。
・神仏分離や寺請制度の廃止により、従来の神仏混交が解消。
・国家神道が形成され、神社は行政組織に組み込まれた。
・仏教・キリスト教への弾圧(廃仏毀釈・五榜掲示)も試みられたが失敗し、神社非宗教論が採用された。
近代化と文化開化 ・欧米からの新学問・芸術・文物が受容され、明治以前とは大きく異なる近代文化が展開。
・言文一致や変体仮名の整理、標準語の普及が進み、近代的な日本語が成立した。
政治指導者 初代内閣総理大臣(首相)に伊藤博文が任命された。
社会的変化 ・欧米式の制度・インフラが急速に整備され、産業・交通・通信が近代化した。
・国家体制の中心が天皇制と官僚制に移行し、近代国家としての基盤が築かれた。
以上が、文献に記載されている明治時代の主要な特徴です。文献に記載がない点については「不明」と答えます。
明治時代は、1868年から1912年までの期間(明治年間)を指し、近代史の一部として位置付けられています。
しかし、具体的な政治・社会・文化的特徴については、提示された文書には記載がないため 不明 です。詳しい情報は「明治」や「日本近代史」などの参照先をご確認ください。
アップロードしたPDFは全く同じものですが、思ったよりチャンクサイズの影響が出ていますね!
そもそもチャンクサイズとは?
この「チャンクサイズ」をざっくり解説すると、ドキュメントをベクトル化(AIが理解・検索しやすいデータ形式への変換)する際に、どのくらいの長さで文章を区切るか、という指定になります。
- 長いチャンク: 前後の文脈を保持しやすいため、複雑な背景を含む質問に強くなります。
- 短いチャンク: ピンポイントな情報の抽出には有利ですが、文脈が断切れになりやすい側面があります。
今回の検証では、明治時代という広範なテーマを扱ったため、チャンクサイズが長い(512)方が、より豊かな文脈を捉えられたようです。
最後に
デフォルトの「multilingual-e5-large」モデルではチャンクサイズは256~512の範囲ですが、最新の「Qwen3-Embedding-4B-FP16」では最大32,000まで指定可能とのこと。実験のしがいがありそうです。
もしAI Engineの活用や、RAG環境の構築についてお困りのことがあれば、ぜひネットアシストにお問い合わせください。
最後までお読みいただき、ありがとうございました!