.png)
こんにちは、UOZUです!
これまでは、主に最新機能や検証内容をご紹介してきましたが、今回からは少し視点を変えて、日々のサーバ運用に役立つ構成や仕組みについて取り上げていきます。
今回のテーマは、WEBサーバの冗長化構成です。
「冗長化」という言葉はよく聞くものの、
実際にどこまで対策すればよいのか、何をもって冗長化と呼べるのかは、構成によってかなり変わります。
たとえば、単純にサーバを2台に増やしただけで、本当に“障害に強い構成”になったと言えるのでしょうか。
今回は、シンプルなWEBサーバ構成を例にしながら、どこに弱点があるのか、そしてどのように改善していくべきかを順番に見ていきます。
冗長化とは
まず最初に、冗長化とは何かを簡単に整理しておきます。
冗長化とは、システムの一部に障害が発生しても、サービスを継続できるように予備の仕組みを持たせることです。
業務で利用しているWEBサイトやシステムは、停止するとそれだけで機会損失や信用低下につながることがあります。
そのため、「壊れたら直す」だけではなく、壊れても止まりにくい構成にしておくことが重要になります。
ただし、冗長化は単に機器や台数を増やすことではありません。
- どこが単一障害点になっているのか
- 障害が起きたとき、どこで切り替えるのか
- 利用者にどのような影響が出るのか
- 運用時に監視や切り分けができるのか
こうした点まで考えて、はじめて「実用的な冗長化構成」になります。
https://cloud.sakura.ad.jp/column/redundantize
冗長化されていない構成のサンプル
それでは、まずは冗長化されていない構成から見てみます。
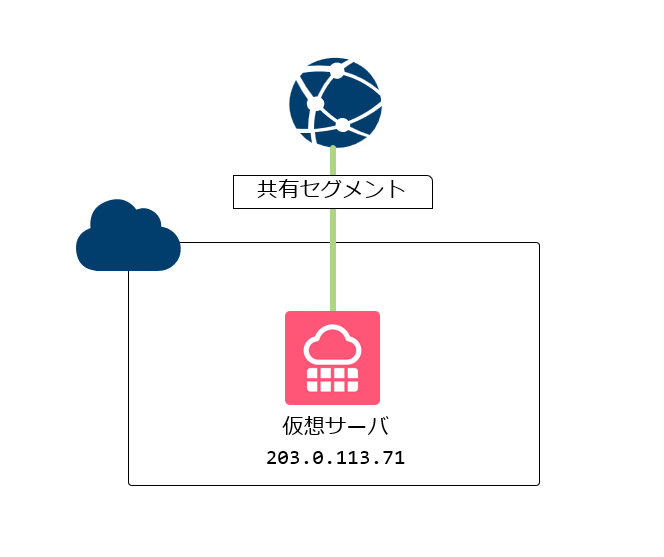
シンプルな1台の構成
もっともシンプルなWEBサーバ構成は、仮想サーバ1台にWEBサービスを載せる構成です。
たとえば、DNSでは以下のように example.com を1つのIPアドレスへ向ける形になります。
| ドメイン | レコード内容 |
| example.com. | A 203.0.113.71 |
この構成は、わかりやすく、最初の構築も比較的簡単です。
小規模な検証環境や、一時的な用途であれば十分に成り立つ場面もあります。
ただし、本番運用を考えると大きな弱点があります。
それは、障害点がすべて1台に集中していることです。
たとえば、以下のようなトラブルが起きた場合、その時点でWEBサイトへアクセスできなくなります。
- 仮想サーバ自体が停止した
- OSが正常に動作しなくなった
- ミドルウェアが停止した
- WEBアプリケーションが応答しなくなった
- メンテナンスや再起動が必要になった
つまり、1台構成はシンプルである一方、どこか1か所でも問題が起きると、そのままサービス停止につながる構成です。
これでは、障害時の業務継続性という観点では十分とは言えません。
「動いている間は問題ない」構成ではあっても、止まったときの逃げ道がないため、冗長化構成としては不十分です。
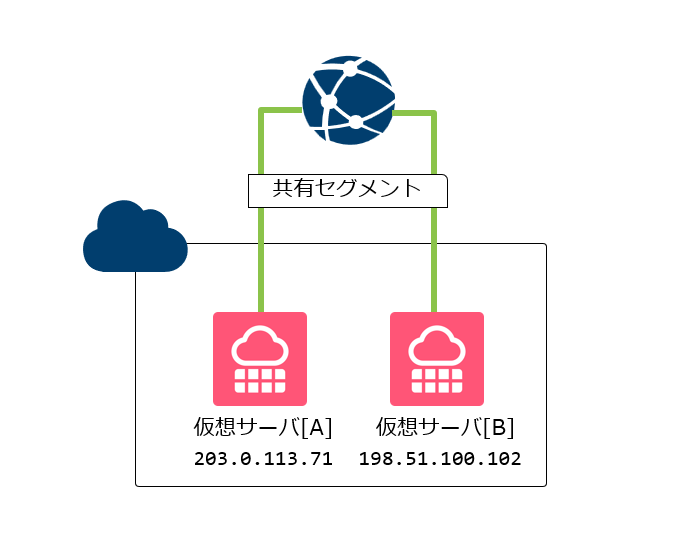
サーバを2台に増やした構成
次に考えやすいのが、仮想サーバを2台に増やす構成です。
たとえばDNSで example.com に対して、2つのAレコードを設定し、サーバ[A]とサーバ[B]の両方へアクセスできるようにする方法があります。
一見すると、これで片方が止まってももう片方が残るため、「冗長化できているように見える」構成です。
| ドメイン | レコード内容 |
| example.com. | A 203.0.113.71 A 198.51.100.102 |
実際、片方のサーバが完全にダウンした場合には、もう片方にアクセスできる可能性があります。
そのため、1台構成よりは改善しているように感じるかもしれません。
しかし、この構成には注意点があります。
一般的なブラウザの動作として、複数のAレコードが存在する場合は、そのうちのどれか1つのIPアドレスへ接続を試みます。
もし接続できなければ、別のAレコードのIPアドレスへ切り替える、という動きになります。
ここで問題になるのは、「接続できるが、中身が正常ではない」ケースです。
たとえば、
- サーバ[A]は正常なコンテンツを返している
- サーバ[B]はWEBサーバ自体は応答するが、アプリケーションエラーやコンテンツ不整合が起きている
という状態だった場合、ブラウザから見るとサーバ[B]は「接続可能」なので、異常なページであってもそのまま表示されてしまいます。
| ダウン状況 | ブラウザ上の表示 |
| 全てのサーバが正常 | 正常な表示 |
| サーバ[A]がダウン サーバ[B]が正常 | 正常な表示 またはアクセスまでに時間がかかる場合がある |
| サーバ[A]がエラー表示 サーバ[B]が正常 | エラーまたは正常な表示のいずれか |
その結果、利用者から見ると、
- ある時は正常なページが表示される
- ある時はエラーページや壊れたページが表示される
という、表示内容がランダムに揺れる状態になります。
これは、サーバやネットワークの面では多少の冗長化になっていても、サービス品質としては安定していない状態です。
さらに、完全ダウンしたサーバへ最初に接続を試みた場合、ブラウザ側で「このサーバには接続できない」と判断してから別IPへ切り替えるため、利用者側で待ち時間や遅延が発生することもあります。
つまり、2台構成にしただけでは、
- 片方に障害があっても、正常系だけに自動で寄せられるとは限らない
- 利用者がエラー画面を見る可能性がある
- 切り替え時の遅延が発生する
という課題が残ります。
「台数を増やすこと」と「安定した冗長化」は、必ずしも同じではない、ということです。
ロードバランサを利用した冗長化構成
ここまで見てきたように、単純にサーバを増やしただけでは、障害時の見え方や切り替え制御まで面倒を見きれません。
そこで有効になるのが、ロードバランサを使った構成です。
ロードバランサを前段に置くことで、利用者は個々のWEBサーバを直接意識せず、
まずロードバランサへアクセスし、そこから正常なサーバへ振り分けられる形になります。
ロードバランサ(L4ロードバランサ)
まず登場するのが、ロードバランサ(L4ロードバランサ)です。
ロードバランサは、主にTCP/UDPなどのトランスポート層で通信を見ながら、接続先のサーバを振り分ける仕組みです。
https://cloud.sakura.ad.jp/products/load-balancer
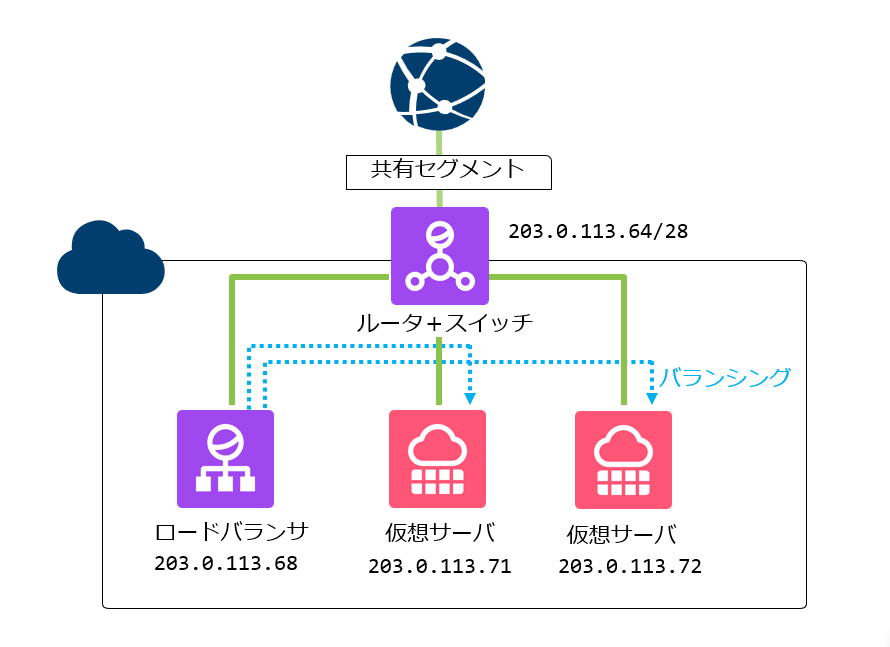
| ドメイン | レコード内容 |
| example.com. | A 203.0.113.68 (ロードバランサのIPアドレス) |
この構成の大きなメリットは、利用者のアクセスを直接サーバへ振らず、ロードバランサ側で制御できることです。
ロードバランサにはヘルスチェック機能があります。
これは、接続先サーバが正常に応答しているかを継続的に確認し、異常があるサーバにはアクセスを流さないようにする仕組みです。
これにより、先ほどの2台構成で問題になっていた点を改善しやすくなります。
たとえば、
- サーバAが停止したら、自動的にサーバBだけへ流す
- 異常を検知したサーバを配信対象から外す
- ブラウザ任せではなく、サーバ側で振り分け判断を行う
といった制御が可能になります。
| ダウン状況 | ロードバランサの制御 | ブラウザ上の表示 |
| 全てのサーバが正常 | いずれかのサーバにアクセスを流す | 正常な表示 |
| サーバ[A]がダウン サーバ[B]が正常 | [B]にアクセスを流す | 正常な表示 |
| サーバ[A]がエラー表示 サーバ[B]が正常 | [B]にアクセスを流す | 正常な表示 |
| 全てのサーバがダウン | 事前に指定したサーバにアクセスを流す | 事前に指定したお知らせ画面(ソーリーページ) |
また、事前に「ソーリーサーバ = アクセスが出来ない際に見せたいサイト」を指定が出来る点も特徴です。
その結果、利用者側から見ると、
- 障害が起きても正常なサーバへ継続してアクセスしやすい
- 切り替え時の待ち時間を減らしやすい
- 異常なサーバをできるだけ踏ませないようにできる
というメリットがあります。
特に、「片系障害が起きたときに、利用者へなるべくエラー画面を見せたくない」という要件では、
L4ロードバランサは非常に有効です。
もちろん、L4ロードバランサにも限界はあります。
L4は基本的に通信レベルでの振り分けが中心のため、
HTTPのパスや内容を細かく見て制御したい場合には、さらに上位の仕組みが必要になることがあります。
それでも、まずはWEBサーバを複数台にして安定運用したい、という段階では、
L4ロードバランサは非常に現実的でバランスのよい選択肢です。
エンハンスドロードバランサ(L7ロードバランサ)
さらに柔軟な制御を行いたい場合は、エンハンスドロードバランサ(L7ロードバランサ)の利用も選択肢に入ってきます。
https://cloud.sakura.ad.jp/products/enhanced-load-balancer
エンハンスドロードバランサは、HTTP/HTTPSの内容を見ながら振り分けができるため、単なる接続先の切り替えだけでなく、よりアプリケーション寄りの制御が可能です。
たとえば、
- 特定のURL配下だけ別サーバへ振り分ける
- ドメインごとに配信先を分ける
- SSL終端をまとめる
- アプリケーション単位でバックエンドを分離する
といった構成が考えられます。
また「さくらのクラウドとさくらのVPSでロードバランシングを行う」といった事も可能な為、より柔軟で弾力性の高い冗長化システムを組むことが可能です。
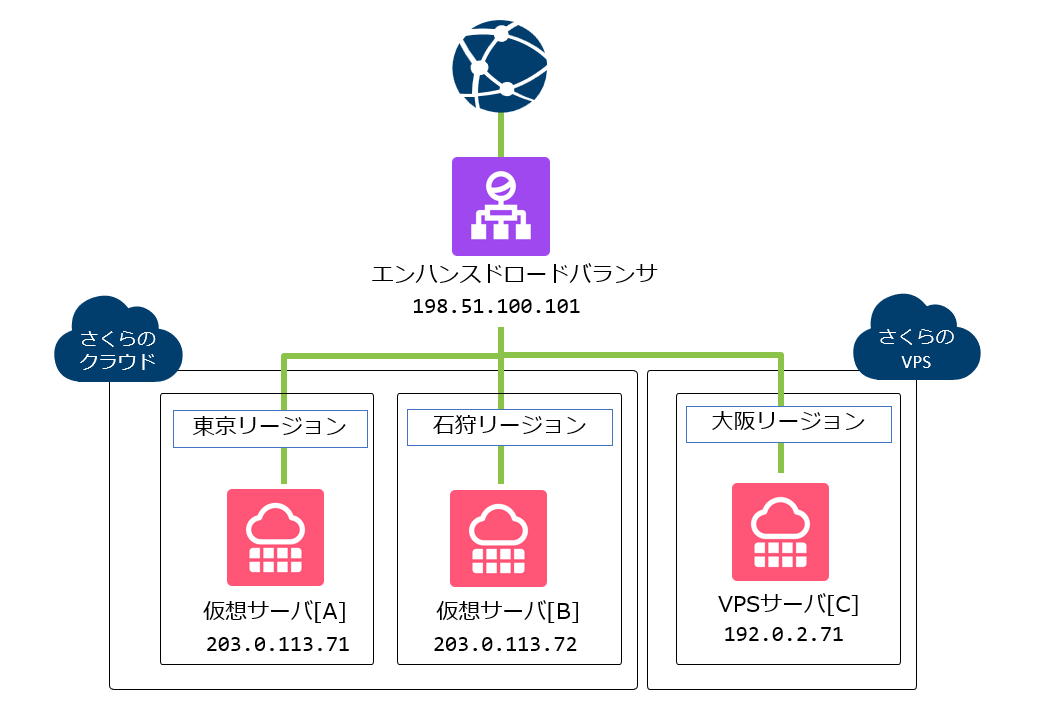
| ドメイン | レコード内容 |
| example.com. | A 198.51.100.101(エンハンスドロードバランサのIPアドレス) |
| ダウン状況 | ロードバランサの制御 | ブラウザ上の表示 |
| 全てのサーバが正常 | いずれかのサーバにアクセスを流す | 正常な表示 |
| サーバ[A]がダウン サーバ[B]が正常 | [B]にアクセスを流す | 正常な表示 |
| サーバ[A]がエラー表示 サーバ[B]が正常 | [B]にアクセスを流す | 正常な表示 |
| 全てのサーバがダウン | 事前に指定したサーバにアクセスを流す | 事前に指定したお知らせ画面(ソーリーページ) |
そのため、単に「止まらない構成」にするだけでなく、機能追加や拡張も見据えたWEB基盤を考える場合には、L7ロードバランサが適している場面があります。
GSLB(広域負荷分散)
冗長化をさらに一段進めると、サーバ単体や同一拠点内の障害だけでなく、拠点全体の障害も考える必要があります。
そこで検討対象になるのが、「GSLB(広域負荷分散)」です。
GSLBは、複数の拠点や複数の環境をまたいでアクセス先を振り分ける仕組みで、たとえば片方のリージョンや拠点で大きな障害が起きた場合でも、もう片方へ誘導する設計が可能になります。
このレベルになると、単なるWEBサーバの冗長化というより、サービス全体の継続性やBCPを見据えた構成になってくるかと思います。
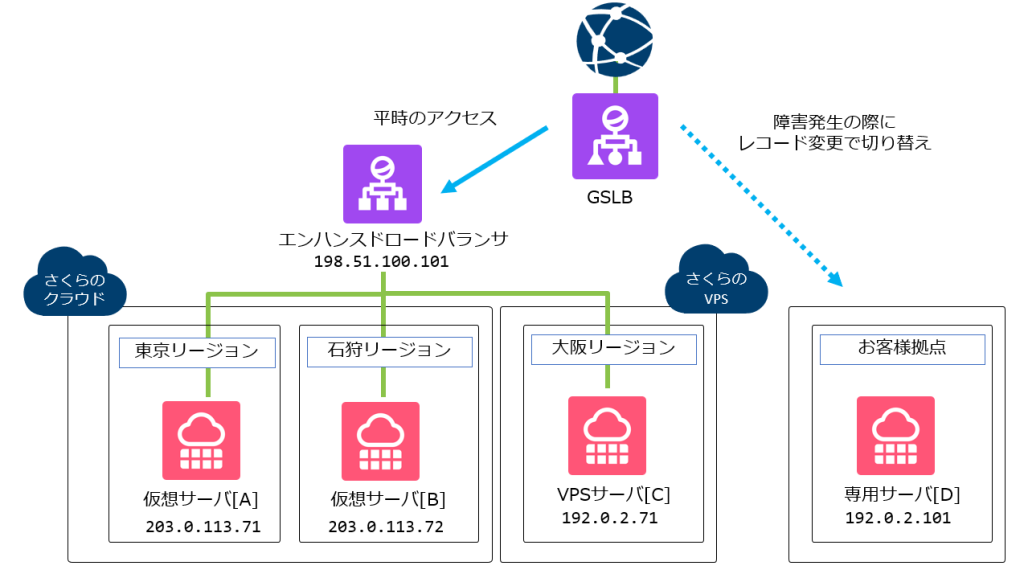
| ドメイン | 障害状況 | レコード内容 |
| example.com. | 正常 | A 198.51.100.101 |
| example.com. | さくらインターネット全体で障害 | A 192.0.2.101 (自動的に変更) |
| ダウン状況 | ロードバランサの制御 | ブラウザ上の表示 |
| 全てのサーバが正常 | [A][B][C]いずれかのサーバにアクセスを流す | 正常な表示 |
| さくらインターネット全体がダウン | [D]にアクセスを流す | 正常な表示 |
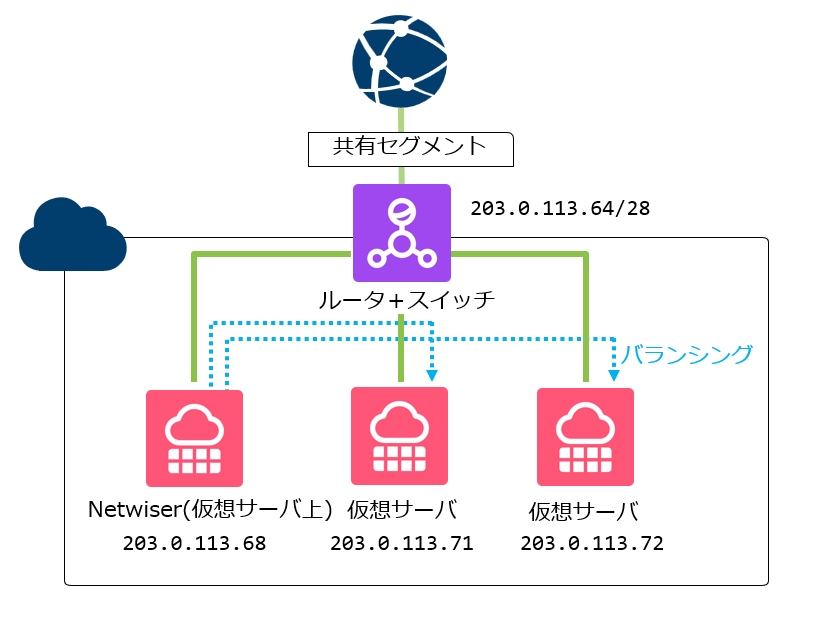
Netwiser
さらに、より柔軟なL4/L7ロードバランサを使いたい場合には、Netwiser も選択肢に入ってきます。
Netwiserは、単にアクセスを振り分けるだけでなく、ロードバランサ機能に加えて、ファイアウォールやWAF連携、ソーリーページの運用 まで含めて考えやすい点が特長です。
https://cloud.sakura.ad.jp/products/netwiser
通常のL4ロードバランサは、主に「正常なサーバへどう振り分けるか」に重点があります。
また、L7ロードバランサは、HTTP/HTTPSの内容を見ながら、URLやドメイン単位で柔軟に振り分けられるのが強みです。
それに対してNetwiserは、負荷分散に加えて、「ソーリーページをNetwiserに持たせて表示する」など、アクセスの入口で必要になりやすい機能を備えています。
ただし、Netwiserは仮想サーバ上で自身でインストールや設定を行う必要があるため、その点は注意が必要となります。
「まずはシンプルに冗長化したい」 という段階では標準のロードバランサが扱いやすい場合もありますし、「より細かい制御や運用要件まで含めて前段を作り込みたい」 場合には、Netwiserのような柔軟性の高い選択肢が活きてくるのではないでしょうか。
さいごに
今回は、WEBサーバの冗長化構成について、基本的な考え方からロードバランサを使った構成まで整理してみました。
ポイントは、サーバを増やすこと自体が目的ではないということです。
大切なのは、障害が起きたときに、
- 利用者にどう見えるのか
- どこで切り替え判断をするのか
- 正常な系へ安定して誘導できるのか
を考えたうえで、適切な構成を選ぶことです。
1台構成はシンプルですが単一障害点を抱えます。
2台構成にしただけでは、表示の揺らぎや切り替え遅延の問題が残ります。
そこで、ロードバランサを活用することで、より実用的な冗長化へ近づけることができます。
次回は、WEBサーバの先にある
DBサーバやストレージを含めた冗長化構成についても触れていきたいと思います。
また、今回紹介したロードバランサ4種は、さくらインターネット様のマニュアルでも比較表がありますので、ご利用検討の際には、併せて参考にいただければと思います。
https://manual.sakura.ad.jp/cloud/support/technical/appliance.html#support-appliance-11
最後までお読みいただき、ありがとうございました!
この記事を書いた人