ネットアシスト開発部のyu-kinjoです。
今回はさくらのクラウドで提供されているマネージドAIサービスである「さくらのAI Engine」を利用してみたいと思います。さくらのAI Engineは複数のAI・LLMモデルやRAG機能がマネージドAPIで提供されるサービスになっています。
今回は汎用的なLLMとして利用できる、OpenAI製オープンソースLLMモデルである「gpt-oss-120b」を利用してみます。自前で高スペックなモデル実行サーバーを構築しなくても、APIから「gpt-oss-120b」を利用し、こちらの用意した指示文「プロンプト」を入力し回答を得る一般的なLLMの処理を実行する事が出来ます。

「さくらのAI Engine」利用開始方法
さくらのクラウドのアカウントを既にお持ちの場合は、管理画面から「さくらのAI Engine」にアクセスする事で利用が開始できます。
今回は説明を割愛しますが、さくらのAI Engineでは2026年2月現在、2つのプランが提供されています。今回は「基盤モデル無償プラン」を利用してみます。表示される利用規約は適切にご確認ください。
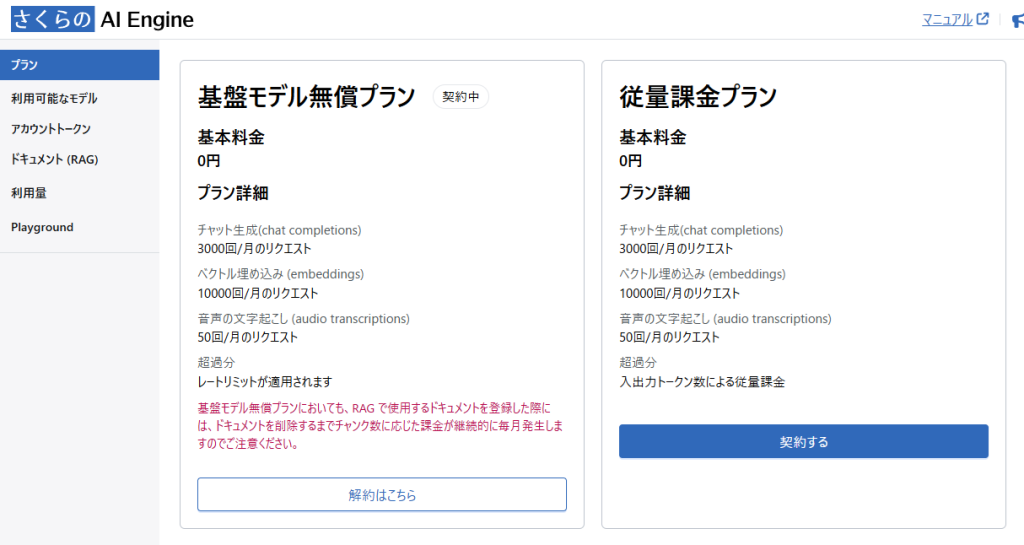
左のメニューを解説していきます。「利用可能なモデル」ではさくらのAI Engineで利用可能なモデルが一覧表示されています。
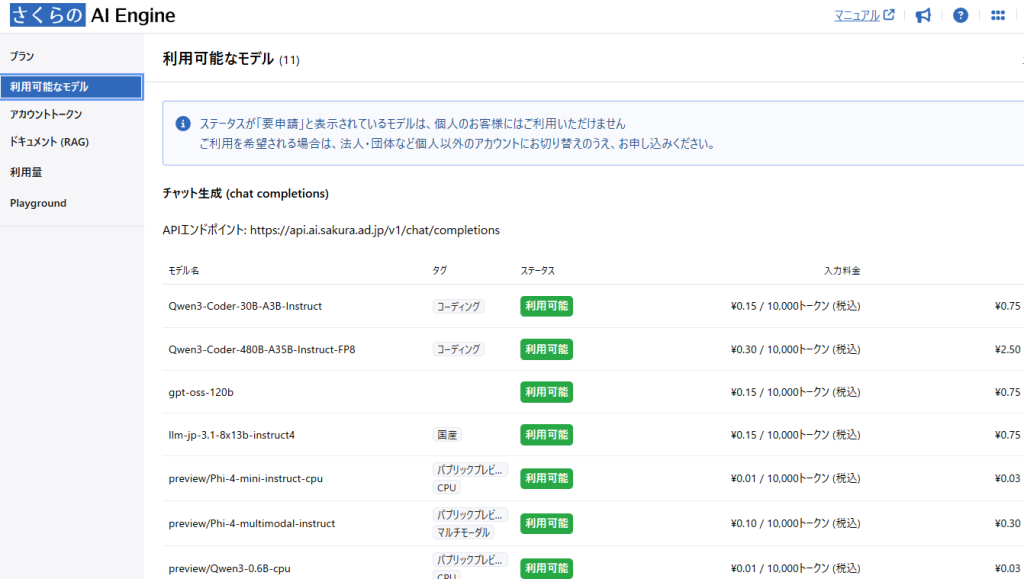
「アカウントトークン」では実際にAPIを利用する際のトークンを作成・管理する事が出来ます。
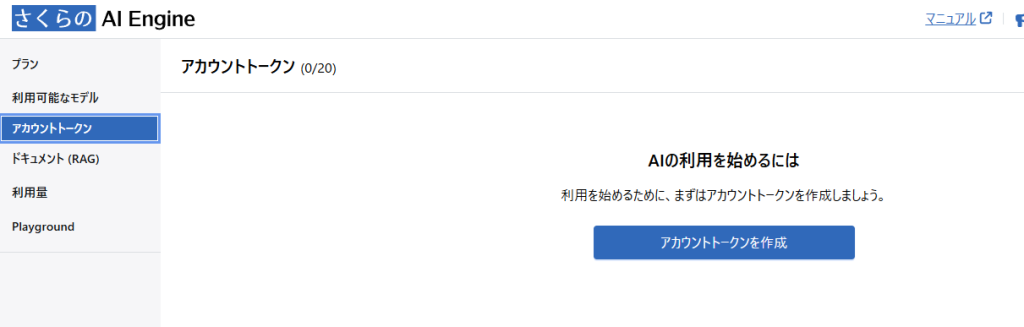
「ドキュメント(RAG)」ではRAG機能で利用しているデータに対するアクセスが行えます。
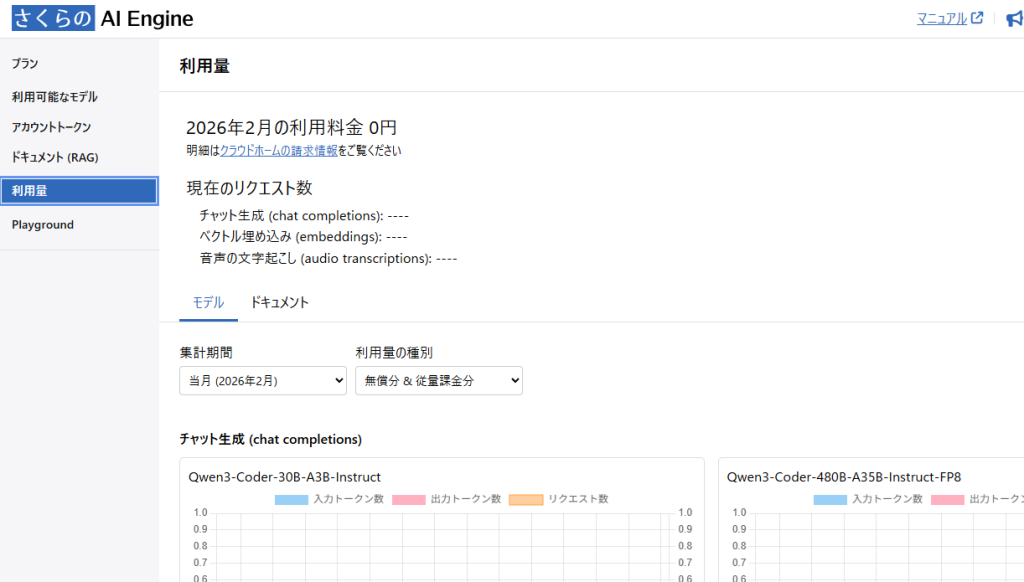
「利用量」では利用量がモデルごとに確認可能です。
「Playground」では、Webブラウザの画面上から任意のモデルに対して実際にチャット上で挙動を確認する事が出来ます。

APIの利用開始
では、実際にAPIにアクセスするためのアクセストークンを作成します。「アカウントトークン」画面で新規のアカウントトークンを作成します。分かりやすいトークン名を設定してください。
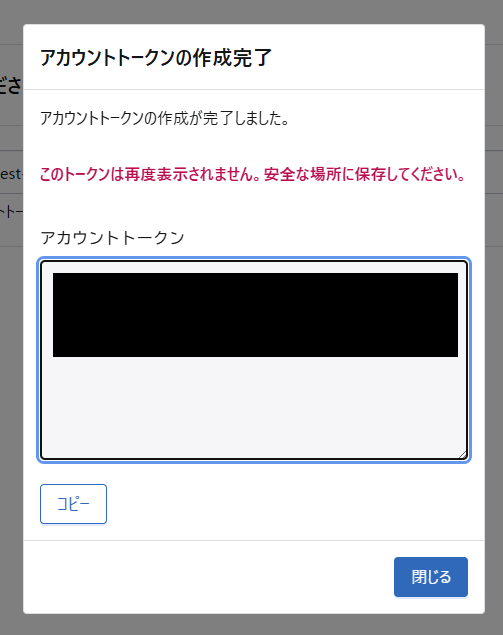
トークンを作成すると、アカウントトークンが表示されます。こちらは再度表示する手段が有りませんので、適切にお手元に控えてください。
APIの実行
アカウントトークンを作成したら、既にAPIの利用が可能な状態です。今回はHTTP通信を行う curl コマンドでAPIの実行を試してみます。回答はJSON形式のテキストで返って来ますので jq コマンドに渡して整形しています。以下の例は、Windows 11の WSL2 上で動作する Ubuntu 24.04 上で実行しています。
$ curl -s --location 'https://api.ai.sakura.ad.jp/v1/chat/completions' \
--header 'Accept: application/json' \
--header 'Authorization: Bearer <<ここにアクセストークンを設定>>' \
--header 'Content-Type: application/json' \
--data '{
"model": "gpt-oss-120b",
"messages": [
{ "role": "system", "content": "こんにちは!" }
],
"temperature": 0.7,
"max_tokens": 200,
"stream": false
}' | jq
{
"id": "chatcmpl-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx",
"object": "chat.completion",
"created": xxxxxxxxxx,
"model": "gpt-oss-120b",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "こんにちは!今日はどのようなお手伝いができますか?",
"refusal": null,
"annotations": null,
"audio": null,
"function_call": null,
"tool_calls": [],
"reasoning_content": "We need to respond as ChatGPT. The user says \"こんにちは!\" which is Japanese greeting \"Hello!\". We should respond accordingly, possibly in Japanese. No special instructions besides that. We can greet back and ask how can help."
},
"logprobs": null,
"finish_reason": "stop",
"stop_reason": null,
"token_ids": null
}
],
"service_tier": null,
"system_fingerprint": null,
"usage": {
"prompt_tokens": 71,
"total_tokens": 142,
"completion_tokens": 71,
"prompt_tokens_details": null
},
"prompt_logprobs": null,
"prompt_token_ids": null,
"kv_transfer_params": null
}<<ここにアクセストークンを設定>>部分に作成したトークンの内容を設定します。また、"content": "こんにちは!今日はどのようなお手伝いができますか?" 部分にプロンプトを設定します。
回答内容として返ってきたJSON内の "content": "こんにちは!今日はどのようなお手伝いができますか?" 部分が、問い合わせた内容の回答結果になっています。これをプログラム上から利用する事で様々なAI処理に活かしていく事が出来ます。
なお、このAPIは送信先のURLにも含まれているように、APIの入力および出力形式は「Chat Completions API」というAPIになっています。OpenAI系のAPIには他に「Responses API」という形式が有るのですが、さくらのAI EngineではResponse APIについてはまだ未対応のようです。こちらについては今後に期待したいですね(※)。
詳細な公式ドキュメントは以下の2つをご参照ください。
さくらのAI Engine | さくらのクラウド マニュアル
さくらの AI Engine Inference API
※2026年05月27日追記: Responses APIに対応しました。以下の記事をご覧ください。
まとめ
「さくらのAI Engine」を利用する事で簡単に有力なOSS LLMモデルである「gpt-oss-120b」を利用する事が出来ました。簡単に使い始められるメリットの他、国内データセンターの国産クラウド基盤上で動作するOSS AI実行基盤という部分も、企業利用で外部利用サービスに制約がある場合にメリットになってくる事も有るかと思います。
Webサーバー、DBサーバー等を組み合わせた基本的なWebシステムに「さくらのAI Engine」を組み合わせる事で、別途高性能なLLM実行用サーバーを用意する事無く、WebサービスにAI実行基盤を組み合わせる構成が実現できます。そういった要件が有る場合はぜひネットアシストへご相談いただけたらと思います。